如何使用SimpleChatGPT与OpenAI愉快的聊天呢?
OpenAI有两种充钱模式,第一种是API充钱,默认成功注册账户后,会赠送5美金的免费使用API额度,用完后就无法聊天了。
还有一个是线上plus,这两个是分开的。
国内不要用虚拟卡充值,容易被封号,虚拟卡的金额也不一定退回,最好的方式是美国账户实名认证一个。
如果两个都充值,plus20$API20$ 一共40$,挺贵的。
目录
1.创建ChatGPT对象.
2.设置OpenAIKey.
3.绑定请求代理
4.简单聊天
5.GPT生成图片
6.GPT结合上下文回复
7.ChatGPT语音识别
8.ChatGPT语音合成
9.IsLeaveUnused
10.麦克风录音
12.麦克风结束录音
13.音频转文字-离线版本
1.我们先创建一个ChatGPT对象,后续的操作都是基于这个对象

其中 Class用默认的SimpleChatGPTObject对象即可,当然也可以在蓝图里面创建一个副本。
2.接下来申请一个OpenAIKey,这个Key需要到OpenAI官网申请,如何申请,网上的讲解非常多,这里就不做过多的介绍了。

3.需要绑定如下代理,因为SimpleChatGPT是异步请求:
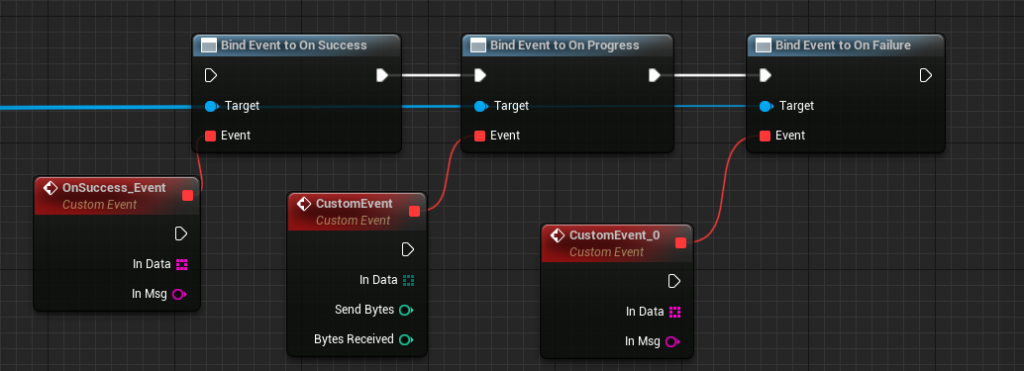
OnSuccess:如果请求成功,会返回一个InData,这里面就是语句。InMag返回是否出错。如果请求的内容是图片,图片的格式是URL。那么InData里面是URL,如果是Base64,那么InData里面是Base64的数据,用户需要解密。
OnProgress:如果采用的是流式传输返回语句,那么这个代理返回InData字节码,如果是语句,用户需要将这个字节码转为FString。
OnFailure:返回错误,InData为空,InMag返回错误原因。
接下来我们介绍一下它具体的API 。一定要确保魔法的定位是美国,否则没有任何效果:
1.RequestByParam
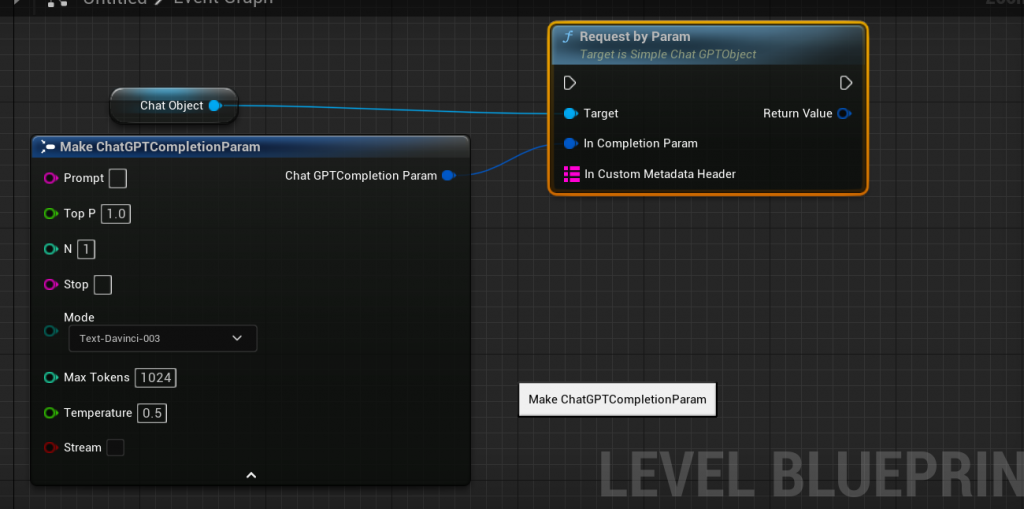
RequestByParam函数 这个函数可以快速的向OpenAI发送聊天语句,可以通过对应的结构参数发送。
我们这边详细介绍一下这个参数:
Prompt:对应的提示,比如向ChatGPT发送一句“你好。”ChatGPT收到后会进行回复。
TopP:控制输出随机性的方式,模型将在每一步选择一个概率分布中的一组单词,这组单词的累积概率不超过 p
N:生成回复数量
Temperature:决定随机性的参数,值接近1,结果越随机,值接近0 输出越确定。
MaxTokens:语句生成的最大长度;
Stop:以什么方式结尾,比如遇到/n就结尾,这里选择为空即可。
Mode:选择GPT模型,有3.5,也有4.0.
steam:是否采用流的方式获取语句,这种反应体验感是最快的,有机会可以体验我们线上的UE5-ChatGPT
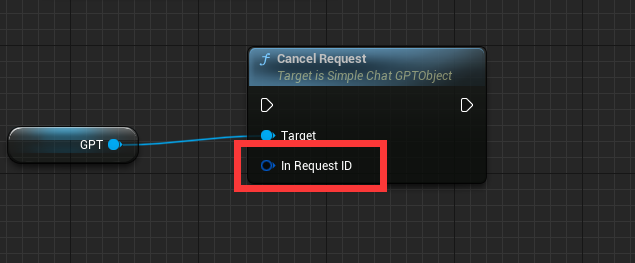
最后会返回一个句柄,该句柄是为了再次控制GPT的输入,比如利用该句柄可以停止GPT语句生成:
最后一个参数是 InCustomMetadataHeader
它主要是为了HTTP自定义头数据准备,也可以为空,传一个空的。
RequestImage
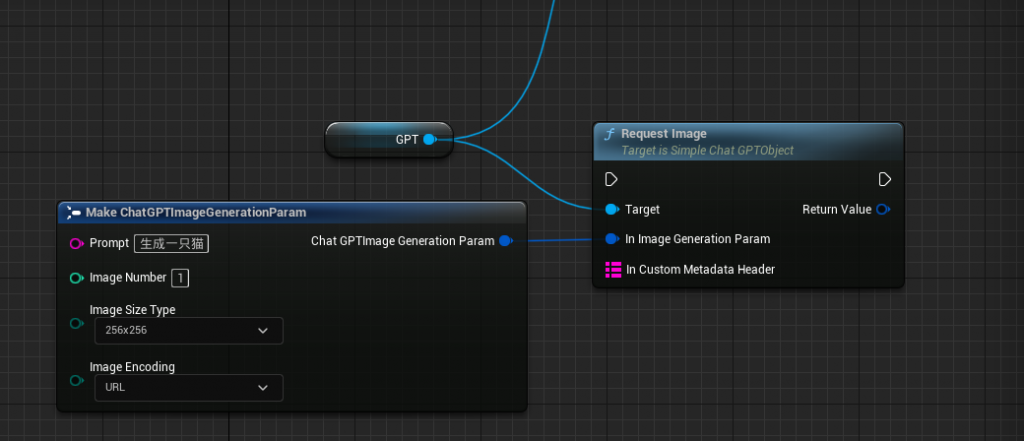
这个API可以帮助您快速通过提示语句生成图片
参数详细讲解:
Prompt:提示,比如生成一只猫。
ImageNumber:希望生成多少张图片
ImageSizeType:生成图片的尺寸大小
ImageEncoding:生成方式,是基于Base64还是URL.如果是Base64那么OpenAI会传回一张图片被加密为base64格式,我们只需要把图片解密保存就可以了。如果是URL,那么还需想OpenAI服务器下载该图片,这些API我们已经做好了,大家可以直接使用。
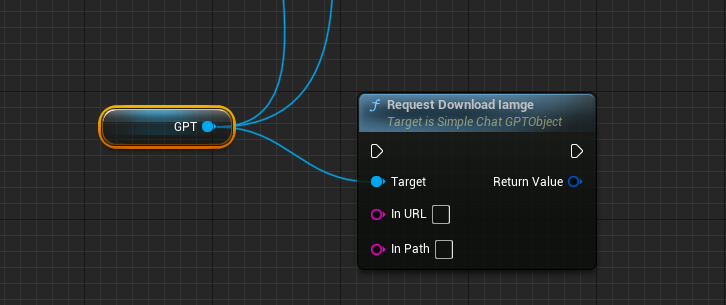
下面的这个API展示了如果您获取的是一个URL应该如何调用API下载。
URL:指定下载的资源URL地址
InPath需要用户指定下载到磁盘的路径。
RequestContext
该API可以结合上下文回复。
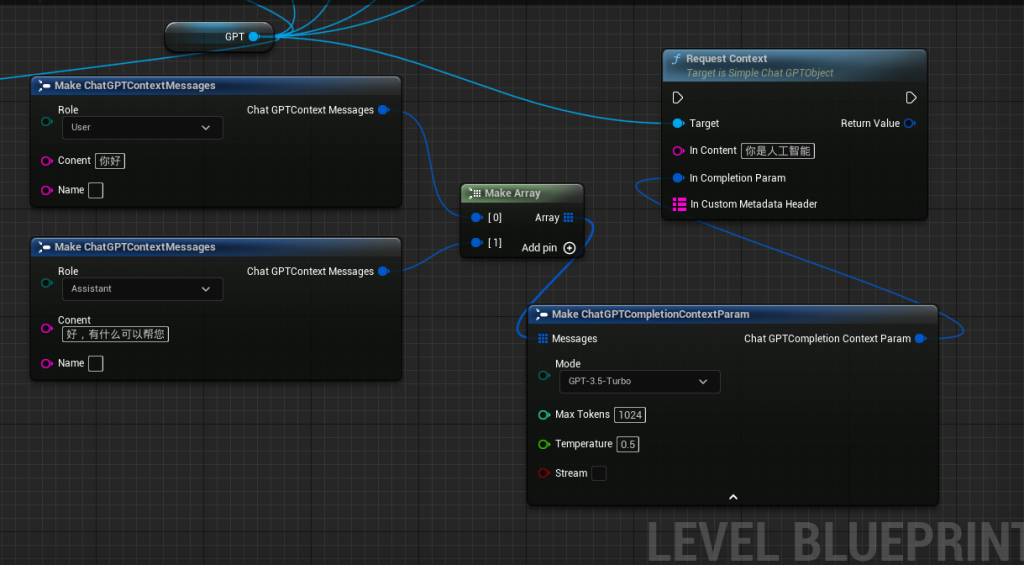
结合上下文需要传入上一次聊天的语句,Role是角色。
Role:User是用户
Assistant:是GPT.
System:系统
其他的内容差不多。
接下来我们介绍一些语音合成和语音识别,这块内容是属于ChatGPT的,需要魔法,对于国内非常不方便,建议用阿里云智能语音来解决这类问题.
IsLeaveUnused:HTTP是否属于闲置状态,这个属于发送一条语句后,这个值为false,等待OpenAI反应,反应结果无论错误还是成功,它都会被设置我true.它的目的是防止一口气发送了多条 语句 。

现在我们来介绍一下ChatGPT的语音识别和语音合成:
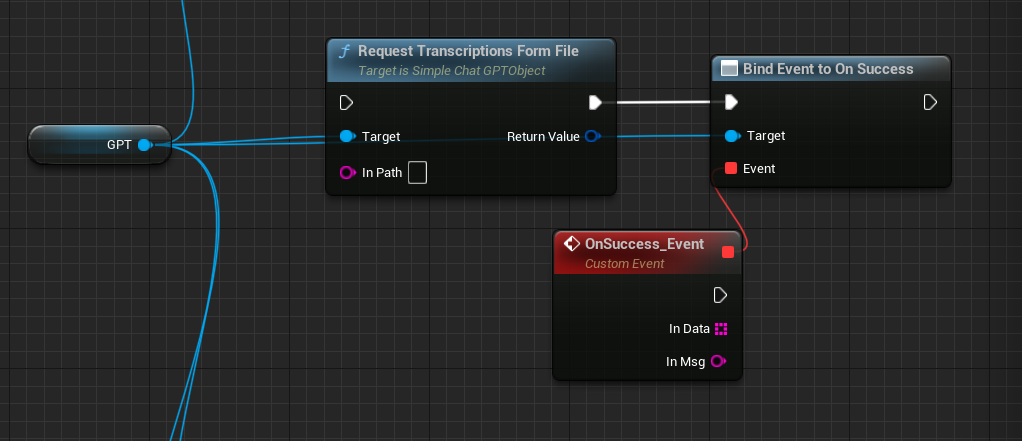
RequestTranscriptionsFormFile:它可以将本地的语音文件,比如.wav格式读取到内存,并且传递到GPT服务器,生成具体的文本。
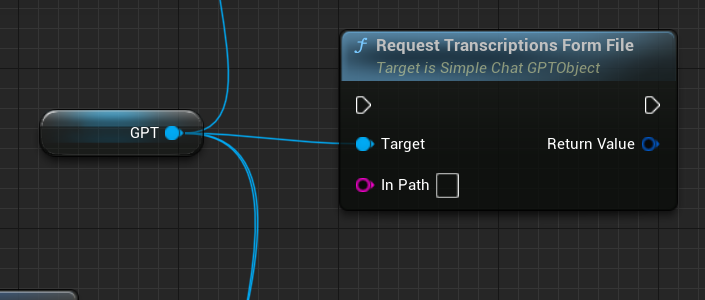
识别后的内容会传递到这个代理 OnSuccess
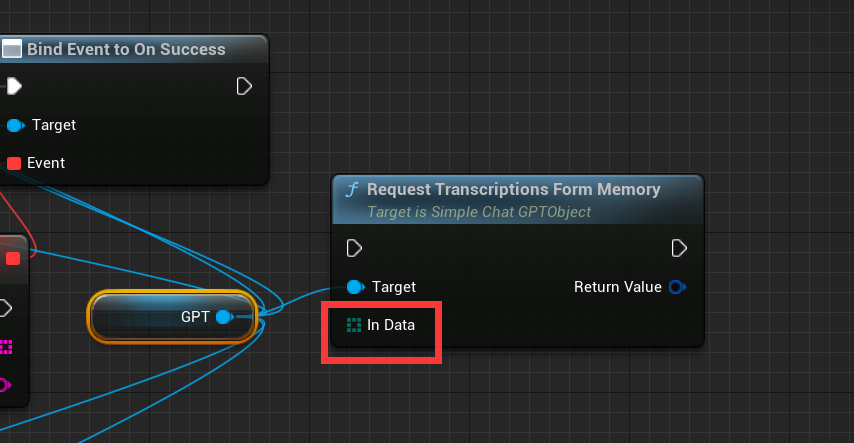
RequestTranscriptionsFormMemory:这个代理是将内存的音频数据上传到GPT服务器,用法和上面文本读取一样,只不过一个是从内存读取,一个是从磁盘读取。
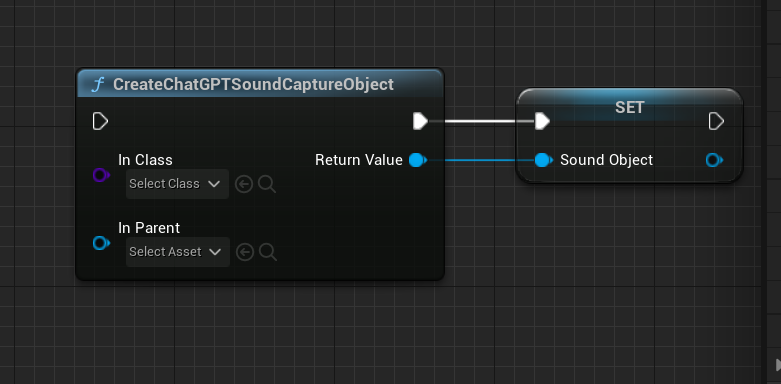
除此之外还有录制麦克风的声音数据,结合上面的介绍的API实现和ChatGPT自由聊天。
1.首先创建一个对象
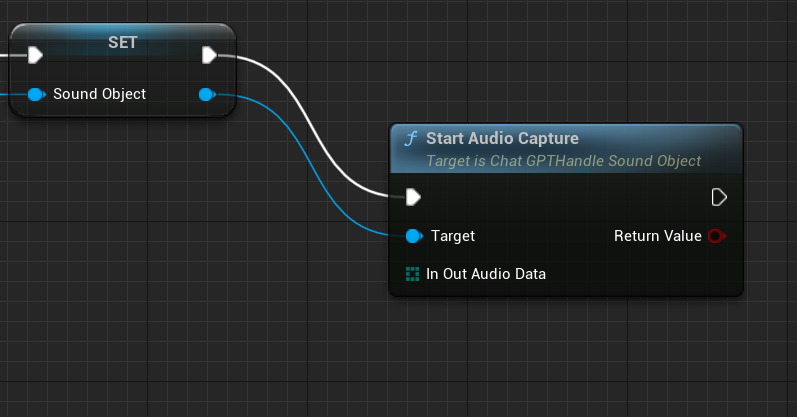
开始捕捉麦克风声音:
确保已经具备了麦克风.
OutAudioData:是输出值,不是输入,它是基于引用地址,只要创建一个数据对象,就可以接受这个数据
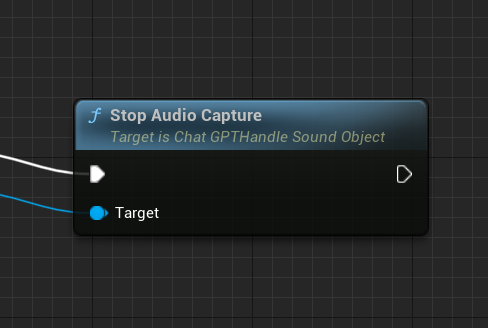
如果想停止录制麦克风可以执行下面的API
除此之外还有 将文本转为语音 :
TextToSpeakAsync:这个是异步操作,不会阻塞主线程。这是一种离线转换,速度非常快。
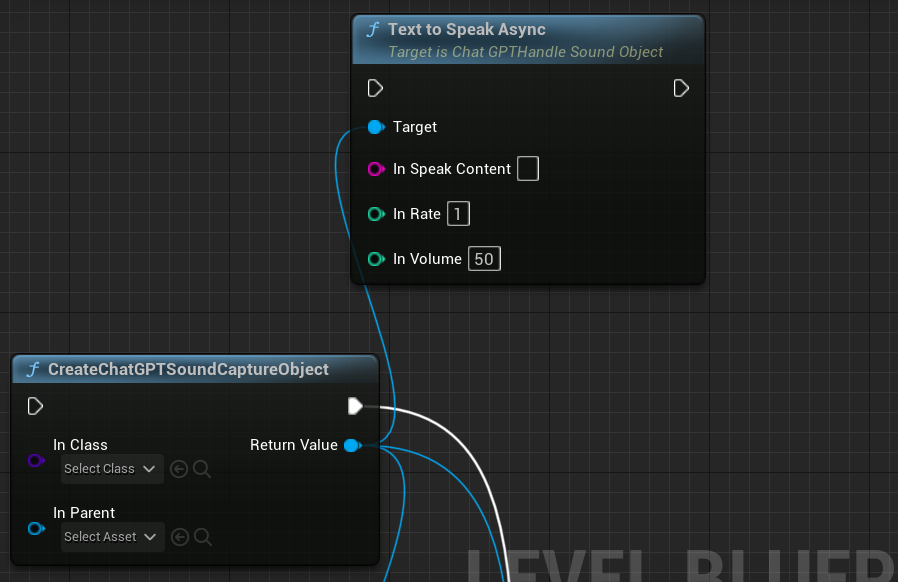
InSpeakContent:要说话的内容,文字,想把它转为音频的文字。
InRate:速率,一般1是标准
InVolune:声音大小,范围是0-100
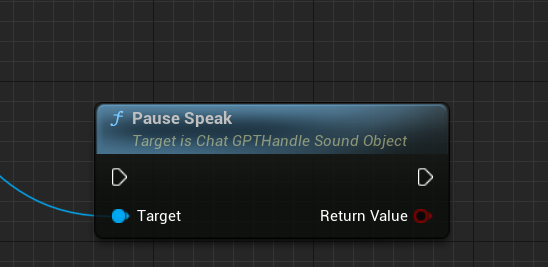
接下来是暂停说话
PauseSpeak:可以暂停说话
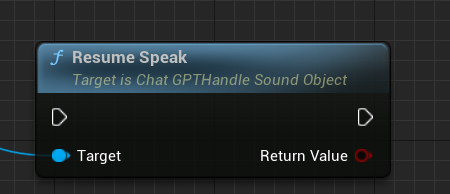
ResumeSpeak:重新开始说话
最后是一些常用的转换API
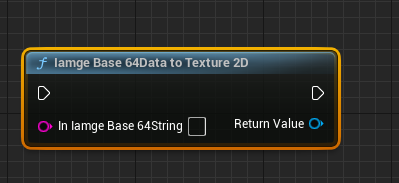
IamgeBase64DataToTexture2D:可以将base64数据转为UTexture2D
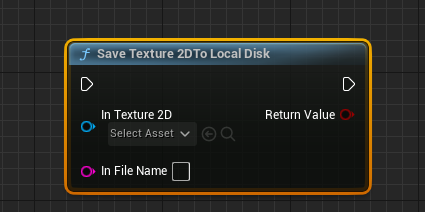
SaveTexture2DToLocalDisk:可以将Texture2D图片存储到磁盘
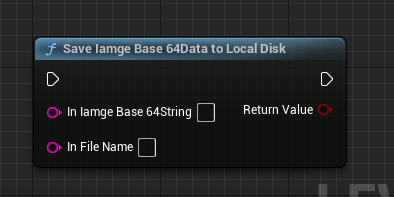
SaveIamgeBase64DataToLocalDisk:直接可以将Base64数据存储到本地磁盘
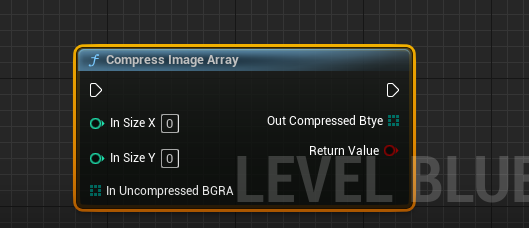
CompressImageArray:对图片进行压缩
一.商业版本和学习版本的对比

二.您还未登陆哦
三.该资源出自以下课程
四.相关解决方案
付费版本包含源码,可以二次开发,如果您不需要二次开发,或者想先试用一下,那么我建议先用免费版本,有的免费版本需要登录。
如果有问题 请加入 售后QQ群:946331852 我们会收集问题,安排维护
如果有希望新增的功能也可以反应到售后,我们会安排添加,感谢理解。

 0
0 








































发表回复
要发表评论,您必须先登录。