注意事项:工程里面不能有空格
目录

请一定用UE5.2引擎打开本工程
NlsConfig.ini配置
测试demo
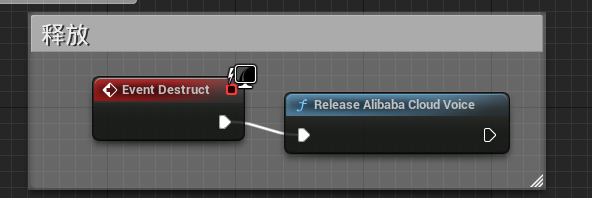
ReleaseAlibabaCloudVoice:释放
SpeechSynthesizer:识别文字并且转为音频数据
NlsInfo:Nls配置
回调:识别后的回调函数参数
SimplePlaySoundByMemory:从内存播放二进制音频数据
SpeechTranscriber:语音合成
Start/EndRecording:录音
SpeechRecognizer:上传要识别的音频
SimplePlaySoundByFile:从本地文件读取二进制音频数据进行播放
PCMToWAVByMemory:PCM格式转为WAV格式从内存转
WAVSaveLocalDisk:存储WAV格式
SetDirectHost:私有云部署IP
SetUseSysGetAddrInfo:DNS获取IP
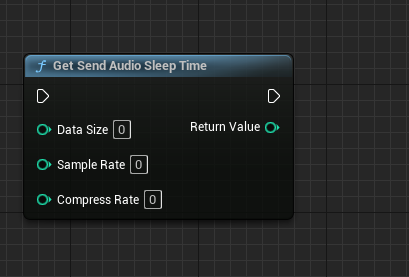
GetSendAudioSleepTime:获取时间
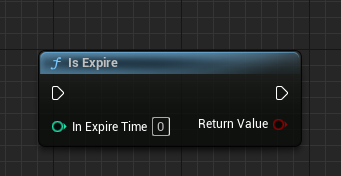
IsExpire:令牌是否超时
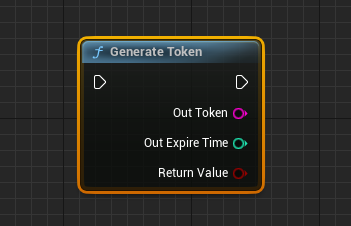
GenerateToken:生成令牌
SetNlsLogConfig:设置Log位置
如果发现无效,请解压插件里面的Engine文件
本插件并非面向蓝图用户,如果是蓝图用户,需要安装VS,并且编译插件的dll和lib,编译成功后再移动到蓝图项目之中,必要的话可能要修改buildID。
UEC++用户无需这些烦恼.
1.请一定用UE5.2引擎打开本工程 如果发现无法打开
请修改 MyProject\Plugins\Binaries\Win64\UnrealEditor.modules 这个文件的buildID 让它的ID和您的引擎的Build一致。
2.打开当前的 MyProject\Config\NlsConfig.ini

AppKey=指定阿里云语言的APPkey
ID=您的阿里云key
Sercet=您的密钥
3.我们准备一个环境,方便大家测试demo的账户,可以手动替换当前目录下的这个NlsConfig.ini文件到项目中的Config下。注意,这个密钥的时间是从2023年7月到2024年7月后过期,仅仅为了测试。
4.如果您打包项目,一定要将插件里面的 这个路径:MyProject\Plugins\Source\ThirdParty\SimpleAlibabaCloudVoiceLibrary\NlsSdk3.X_win64\lib\14.0\x64\Release\
下的lib和dll拷贝到你的项目 MyProject\Binaries\Win64\下 蓝图项目不会自动拷贝,这个我们也头大。
教程

ReleaseAlibabaCloudVoice:结束后别忘记释放(新版本已经丢弃)
SpeechSynthesizer:识别文字并且转为音频数据
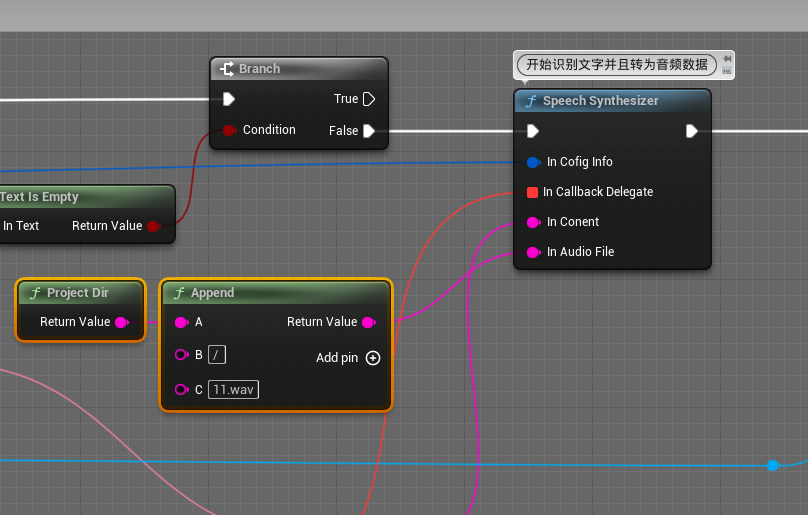
CallbackDelegate:识别完成后会调用该代理。
Content:需要输入的内容,比如“你好” 发送到阿里云服务器 它会将你好合成语音。
AudioFile:可以将音频数据保存到指定的目录下。
ConfigInfo:配置信息。
NlsInfo:阿里云智能语音配置清单。

EncodingFormat:输出的编码格式,设置音频数据编码格式。可选参数,目前支持PCM/OPUS,默认为PCM。
SampleRate:采样率,设置音频数据采样率。可选参数,目前支持16000/8000。默认为16000。
IntermediateResult:设置是否返回中间识别结果。可选参数,默认false。
PunctuationPrediction:设置是否在后处理中添加标点。可选参数,默认false。
InverseTextNormalization:设置是否在后处理中执行ITN。可选参数,默认false。
MaxSentenceSilence:语音断句检测阈值,一句话之后静音长度超过该值,即本句结束,合法参数范围200ms~2000ms,默认值800ms。
EnableVoiceDetection:启用语音检测
MaxStartSilence:最大开始语句
MaxEndSilence:最大结束语句
CustomizationId:定制语言模型id,可选。
VocabularyId:定制泛热词id,可选。
PayloadParam:用于传递某些定制化、高级参数设置,参数格式为JSON格式:{ “key”: “value” }。
OutputFormat:UTF-8 or GBK 输出格式 如果不想出现乱码 就utf8
AutomaticallyPlaySound:是否自动播放下载的数据
Teller:讲述人设置
VolumeValue:音量, 范围是0~100, 可选参数, 默认50
SpeechRate:语速, 范围是-500~500, 可选参数, 默认是0
PitchRate:语调, 范围是-500~500, 可选参数, 默认是0
EnableSubtitle:开启字幕
QueuePlay:是否队列播放使用,需要AutomaticallyPlaySound=true才有效。如果同时获取多个音频,按照给定的顺序播放,其他的音频会存起来等待播放。
回调:

StatusCode:HTTP状态码,200为正常。
Msg:如果出错,这里面会有值
MsgType:是语音合成还是语音识别各种阶段的类型
TaskId:当前的任务ID,
Result:如果是语音识别,这里面就是具体的识别内容
DisplayText:显示的Text
SpokenText:Text
SentenceTimeOutStatus:语句的超时状态,这个按照阿里云那边的状态
SentenceIndex:语句的Index
SentenceTime:花费的时间
SentenceBeginTime:开始的时间
SentenceConfidence:
Data:服务器获取的二进制数据,可以是音频,也可以是其他。
SimplePlaySoundByMemory:从二进制数据播放声音

SpeechTranscriber:语音合成,可以直接捕捉麦克风的声音并且上传到服务器进行合成
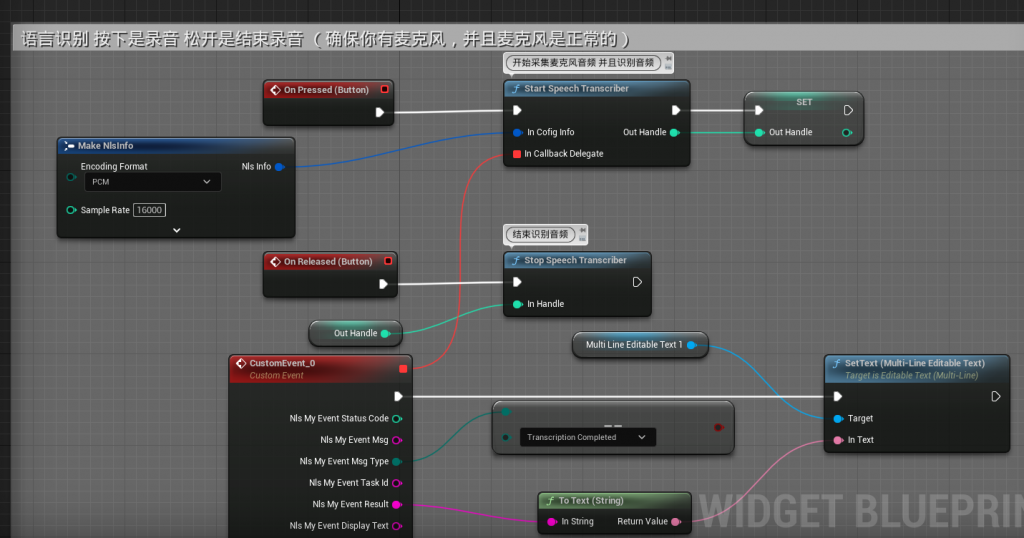
Start/EndRecording:单纯的录音功能,将录音数据保存的本地
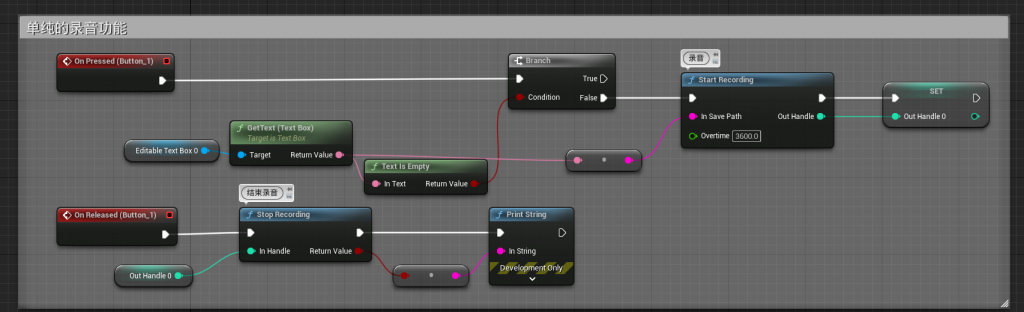
SpeechRecognizer:读取本地的音频文件 上传阿里云识别。

SimplePlaySoundByFile:从本地文件读取二进制音频数据进行播放

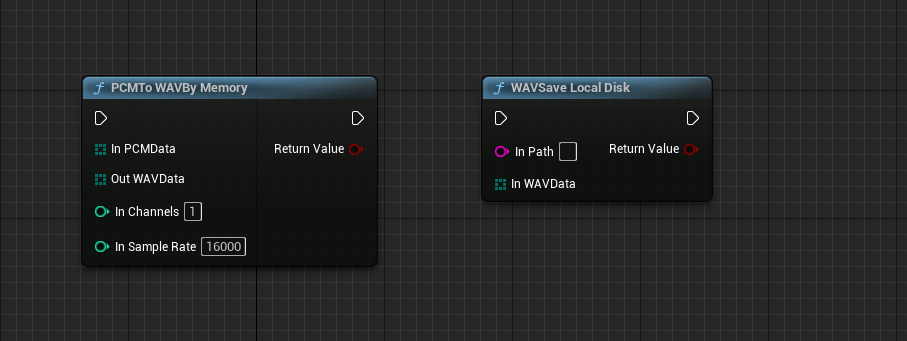
PCMToWAVByMemory:PCM格式转为WAV格式,需要输入对应的通道和采样率。
WAVSaveLocalDisk:将WAV格式保存到磁盘。
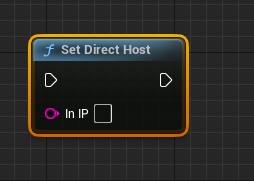
SetDirectHost:私有云部署的情况下可进行直连IP的设置【必须在StartWorkThread()前调用】
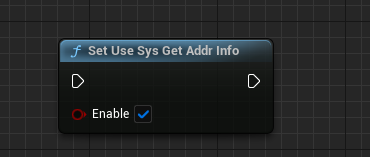
SetUseSysGetAddrInfo:存在部分设备在设置了dns后仍然无法通过SDK的dns获取可用的IP,可调用此接口主动启用系统的getaddrinfo来解决这个问题.
GetSendAudioSleepTime:
@brief 获取sendAudio发送延时时间。
@param dataSize 待发送数据大小。
@param sampleRate 采样率:16k/8K。
@param compressRate 数据压缩率,例如压缩比为10:1的16k OPUS编码,此时为10,非压缩数据则为1。
@return 返回sendAudio之后需要sleep的时间。
@note 对于8k pcm 编码数据, 16位采样,建议每发送1600字节 sleep 100 ms.
对于16k pcm 编码数据, 16位采样,建议每发送3200字节 sleep 100 ms.
对于其它编码格式(OPUS)的数据, 由于传递给SDK的仍然是PCM编码数据,
按照SDK OPUS/OPU 数据长度限制, 需要每次发送640字节 sleep 20ms.
IsExpire:令牌是否会过期,令牌的生成在内部是自动的。
GenerateToken:手动生成令牌
SetNlsLogConfig:设置Nls日志 一般可以不用设置,系统会默认设置。

维护日志
2023年6月26日:优化了蓝图调用参数,去除是否开启全局配置。更新的案例demo.
2023年7月3日:语音识别打包后的奔溃问题,新增语音识别通过独立程序,增加独立程序
2023年7月13日:增加免费蓝图5.10版本,隐藏窗口调用。
2023年7月15日:增加了异步声音方法.
2023年7月17日:解决了配置声音大小和语调,音调没有反应的问题。
2023年8月17日:移除开启线程功能,打包后不会影响其他HTTP功能的bug(这个bug解决了一星期)
2023年11月25日:解决语音识别无法结束的问题
2023年12月5日:语音识别-蓝图奔溃问题
2023年12月20日:解决录音卡死问题
一.商业版本和学习版本的对比

二.您还未登陆哦
三.该资源出自以下课程
四.相关解决方案
付费版本包含源码,可以二次开发,如果您不需要二次开发,或者想先试用一下,那么我建议先用免费版本,有的免费版本需要登录。
如果有问题 请加入 售后QQ群:946331852 我们会收集问题,安排维护
如果有希望新增的功能也可以反应到售后,我们会安排添加,感谢理解。

 0
0 








































[…] 接下来我们介绍一些语音合成和语音识别,这块内容是属于ChatGPT的,需要魔法,对于国内非常不方便,建议用阿里云智能语音来解决这类问题. […]
你好,阿里云的插件不太稳定,请问会维护更新吗
一直在维护,是哪里有问题?
阿里云语音插件有5.1版本吗
高版本也可以在低版本使用
用了代码版的插件,蓝图里出了个错误 start work thread报错了,没法用了
用最新版本的,新版本StartWorkTread 废弃
支持安卓打包吗?
不支持
你好,我购买了你的阿里云的语音识别和千问的插件。在ue5想简单的实现,话筒识别声音,通过千问回答,最后语音合成的功能。发现就是不能播放出来声音。在线着急,大佬帮我看看蓝图设置有什么问题。可以付费远程。我的qq 610946857
加入售后群
购买了插件不太会用,新手,售后群一直没通过,挺着急的
有教程
[plug]SimpleAlibabaCloudVoice 5.32您好,请问下为什么这个版本解压后里面没有source文件呀?需要怎么解决呀?
你用的是免费版本 免费版本蓝图直接可以启动